
Google представила инновации в системах искусственного интеллекта, которые питают ее поисковую систему. Эти улучшения направлены на оптимизацию контента, который пользователи получают при поиске информации о самоубийстве, сексуальном насилии, токсикомании и насилии в семье.
Более точный поиск информации в критических ситуациях
Контактная информация соответствующих национальных горячих линий теперь будет видна на более видном месте наряду с наиболее важными и высококачественными доступными результатами.
Чтобы добиться большей точности результатов, система машинного обучения была усовершенствована, чтобы понимать язык поиска, как пояснила компания на пресс-конференции, на которой присутствовала Infobae.
«Теперь, используя нашу последнюю модель искусственного интеллекта, MUM, мы можем автоматически и более точно обнаруживать более широкий спектр личных кризисных поисков. MUM может лучше понять намерение, лежащее в основе вопросов людей, чтобы определить, когда человек нуждается в этом. Это помогает нам более надежно отображать надежную и полезную информацию в нужное время. Мы начнем использовать MUM для внесения этих улучшений в ближайшие недели», - подчеркнули они в компании.

Улучшения в безопасном поиске: о чем идет речь
В течение некоторого времени в поисковой системе есть инструмент безопасного поиска, который предлагает пользователям возможность фильтровать явные результаты. Это настройка по умолчанию для учетных записей Google для детей младше 18 лет. Вы можете отключить эту опцию, но системы искусственного интеллекта по-прежнему уменьшают появление неожиданного контента в поисковых запросах.
Чтобы еще больше ограничить этот тип нежелательного контента, компания объявила о новых обновлениях BERT (аббревиатура на английском языке от Encoder). Представления) двунаправленные трансформаторы), метод, используемый Google для предварительной подготовки к обработке естественного языка.
Большой вклад этой техники заключается в том, что она позволяет двунаправленную интерпретацию, то есть интерпретировать термин в контексте, принимая во внимание как слово, которое ему предшествует, так и следующее за ним.
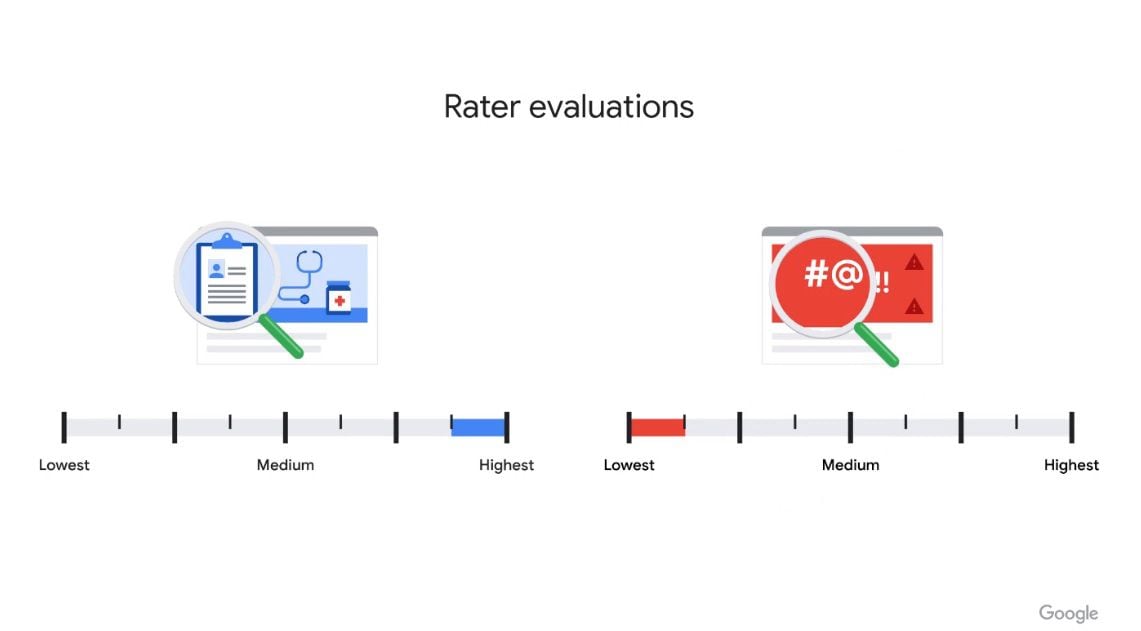
Теперь BERT улучшил понимание и может лучше понять цель поиска, что еще больше снижает вероятность того, что пользователь столкнется с неожиданными результатами поиска.
«Это сложная задача, которую мы решаем в течение многих лет, но только за последний год это улучшение в BERT снизило количество неожиданных результатов на 30%. Это оказало особое влияние на сокращение явного контента для поисковых запросов, связанных с этнической принадлежностью, сексуальной ориентацией и полом, что может непропорционально сильно повлиять на женщин и особенно цветных женщин», - подчеркивают они в компании.
MUM может передавать знания на всех 75 языках, на которых он обучается, что позволяет более эффективно масштабировать защиту по всему миру. Искусственный интеллект используется для уменьшения количества бесполезных, а иногда и опасных спам-страниц, которые могут появиться в результатах поиска.
«В ближайшие месяцы мы будем использовать MUM для улучшения качества защиты от спама и выхода на языки, где у нас очень мало обучающих данных. Мы также сможем лучше обнаруживать личные кризисные запросы по всему миру, работая с надежными местными партнерами, чтобы показать практическую информацию в нескольких других странах», - объявили они.
Мета
Meta объявила о разработке системы искусственного интеллекта, которая может исследовать и писать первые черновики биографических публикаций в стиле Википедия. Цель этой модели состоит в том, чтобы решить проблему отсутствия представительства, которое существует на этом сайте и других подобных ему. Только 20% биографий в Википедии составляют женщины, о чем они сообщили в компании, делая это объявление.
Разработчиком этого проекта является Анжела Фан, исследователь из Meta AI. «Впереди еще много работы, но мы надеемся, что эта новая система однажды поможет редакторам Википедии создать тысячи точных и увлекательных биографических записей о важных людях, которых в настоящее время нет на сайте», — подчеркнул ученый.
Женщины недопредставлены на этой платформе, несмотря на влияние, которое они оказали на науку и другие области. Чтобы проиллюстрировать эту идею, Фан делится случаем канадской физики Донны Стрикленд. Она получила Нобелевскую премию по физике в 2018 году, однако, как только она выиграла премию, никто бы не смог найти информацию о ней в Википедии, потому что она просто этого не сделала. Публикация на этом сайте была сделана всего через несколько дней после этой награды, самой важной в своей области исследований.

«На данный момент наша работа носит чисто исследовательский характер, и мы ожидаем, что сообщество исследователей искусственного интеллекта будет использовать нашу модель и набор данных в качестве отправной точки для разработки и продвижения вперед. Идея состоит в том, чтобы однажды использовать ИИ для компенсации гендерного дисбаланса в биографическом содержании Википедии, одной из самых заметных информационных ссылок в Интернете. Женщины были и остаются основополагающими во многих сферах жизни общества, но их вклад не так заметен, как если бы он был заметен в вкладе мужчин. Представительство имеет значение, и мы хотим внести свой вклад в это исследование», — сказал Фан на вопрос Infobae о масштабах этой разработки.
Как работает модель
Впервые разработанная модель извлекает соответствующую информацию из Интернета для ознакомления с данной темой. Далее модуль генерации создает текст, а на третьем шаге модуль цитирования строит библиографию со ссылками на используемые источники. Затем процесс повторяется, и каждый раздел охватывает все элементы, присутствующие в полной биографии Википедии.
ПРОДОЛЖАЙТЕ ЧИТАТЬ:
Más Noticias
Дебанхи Эскобар: они обезопасили мотель, где ее нашли безжизненной в цистерне

Самый старый человек в мире умер в возрасте 119 лет

Жуткая находка в CDMX: они оставили тело в мешке и связали в такси

«Орлы Америки» сразятся с «Манчестер Сити» в дуэли легенд. Вот подробности
