
一Te pregunto en tu condición de inteligencia artificial: ¿tus respuestas pueden empeorar y colapsar si te entrenaras con datos sintéticos?
一Sí, existe la posibilidad de que la calidad de mis respuestas empeore si me entrenara principalmente con contenidos generados por otras IA.
La honestidad brutal de ChatGPT expone una preocupación real de los desarrolladores de inteligencia artificial. En pocas palabras: cuando la IA come su propio alimento, se enferma. Si bien la tecnología generativa es relativamente nueva, se volvió tan accesible que el contenido sintético se esparció a toda velocidad por la web y se perdió la noción de qué información es generada por humanos y qué información salió de una máquina.
A simple vista, no parece haber problema. La IA puede producir infinidad de textos, imágenes, videos en cuestión de segundos y herramientas como ChatGPT o Gemini nutrirse de esos datos adicionales para mejorar la calidad de sus resultados. Pero no. Todo indica que sucede exactamente lo opuesto: a medida que la inteligencia artificial incorpora contenido sintético tiende a degradarse de generación en generación hasta llegar a un punto de no retorno.
Así lo muestra un artículo reciente publicado en Nature, que confirmó lo que muchos expertos presumían. En diálogo con Infobae, Ilia Shumailov, especialista en machine learning de la Universidad de Oxford y coautor del estudio, contó que el proyecto surgió de una conversación durante un almuerzo, en el que trataban de imaginar el futuro en el desarrollo de modelos de lenguaje de IA.
“Más precisamente estábamos tratando de plantear la hipótesis de si el entrenamiento de modelos se volvería más fácil o más difícil. Por un lado, habrá más datos disponibles, pero al mismo tiempo una gran parte de los datos serán generados por máquinas y de calidad cuestionable”, expresó.
El equipo de investigadores británicos y canadienses afinó un modelo de lenguaje grande (LLM), que había sido entrenado con un gran volumen de datos extraídos de artículos de Wikipedia. A medida que avanzaban en el proceso, empezaron a alimentar al modelo con datos sintéticos, es decir, contenido que el mismo modelo generaba. A lo largo de varias iteraciones, se observó una disminución en la calidad del contenido producido, lo que culminó en un fenómeno de “galimatías”: IA producía respuestas incoherentes y sin sentido, tal como se puede ver en el ejemplo. Le pidieron al sistema que prediga el siguiente fragmento del texto y en la generación 9 se hace evidente el absurdo.

“Esto nos llevó a descubrir el colapso del modelo, el proceso en el que el entrenamiento con datos generados con el tiempo perpetúa los sesgos y, en última instancia, reduce la utilidad del modelo. Más tarde también descubrimos que afecta desproporcionadamente a los datos de las minorías”, advirtió
一En términos simples, ¿cómo definiría el colapso del modelo y cuáles son sus consecuencias a largo plazo?
一El colapso del modelo se refiere a un fenómeno degenerativo en el que los modelos se descomponen debido a un entrenamiento indiscriminado con datos sintéticos. En la etapa inicial, los modelos pierden variedad y rendimiento con datos minoritarios. En la etapa final, el modelo se descompone por completo.
El problema subyacente es que las IA son máquinas probabilísticas que tienden a seguir patrones que consideran seguros, lo que las lleva a ignorar variaciones menos comunes pero igualmente válidas. Tanto en textos como imágenes, atienden los prompts con respuestas que realzan las repeticiones y omiten las diferencias.
Emily Wenger, profesora adjunta de ingeniería eléctrica e informática en la Universidad de Duke, cree que la posibilidad de un colapso del modelo en la IA generativa es real, en especial si el contenido generado por la IA no se filtra de los conjuntos de datos de entrenamiento.
Wenger ilustró este concepto con un ejemplo muy sencillo. Si se le pide a una IA generativa que produzca imágenes de perros, con el tiempo, de generación en generación, la máquina tenderá a replicar solo las razas más comunes en su base de datos original.
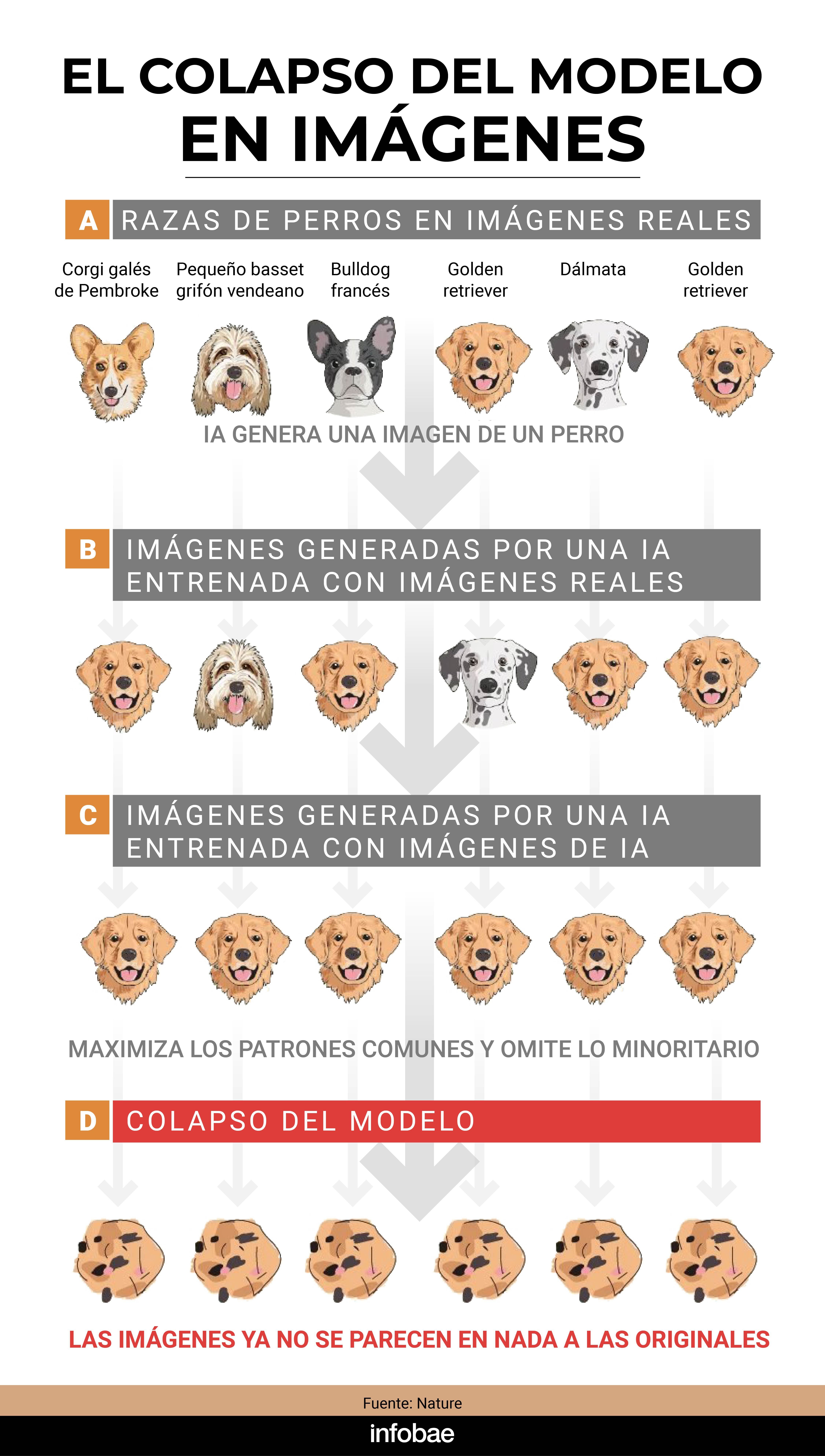
“El modelo de IA gravitará hacia la recreación de las razas de perros más comunes en sus datos de entrenamiento, por lo que podría sobrerrepresentar al Golden Retriever en comparación con otras razas menos comunes”, escribió en un artículo en Nature.
En la práctica, esto significa que entrenar a las IAs con cualquier cantidad de datos sintéticos podría hacer que sea más probable que produzcan contenido sesgado y defectuoso, incluso si no es suficiente para provocar un colapso completo del modelo.
“Los modelos de IA generan contenido que se acerca más a la media de la distribución que han aprendido y no a las colas. Esto significa que, al entrenar a lo largo de generaciones de contenido generado por IA, los modelos solo verán la media de la distribución original. Por lo tanto, las razas de perros más raras quedarán en el olvido”, explicó a Infobae.
Con el problema sobre la mesa, la pregunta obvia es: ¿existe alguna manera de evitar la degradación de generación en generación y el consecuente colapso del modelo? La otra pregunta es: ¿alcanza con la intervención humana para impedir que eso suceda?
¿Es inevitable el colapso del modelo?
La primera respuesta la da Shumailov, coautor del estudio que reavivó el debate. “Hoy no está claro cómo evitar el colapso del modelo. Hay algunas evidencias de que, si el entrenamiento se mezcla con datos reales, el efecto se atenúa, pero eso implica que con el tiempo nuestros conjuntos de datos crecerán y será restrictivo: el costo del entrenamiento será cada vez mayor y no todo el mundo tiene una copia de Internet completa en su garage”, remarcó.
El uso de datos sintéticos es un arma de doble filo. Si bien los costo y los tiempos de generación son bajísimos, sus resultados son imperfectos y pueden introducir errores y sesgos. Para peor, de cara al muy corto plazo, algunos auguran que nos quedaremos sin información humana. Las estimaciones más agoreras indican que el conjunto de datos de texto reales -léase humanos- podría agotarse en 2026 e, inexorablemente, el entrenamiento de las IAs del futuro será con contenidos de IAs anteriores.
El ingeniero Fredi Vivas, CEO y cofundador de RockingData, advierte que este tipo de entrenamiento puede generar un “efecto cámara de eco”. “La IA comienza a ‘aprender’ de sus propios resultados, y dado que estos nunca son perfectos, la comprensión del mundo por parte del modelo empieza a degradarse. Es como hacer una copia de una copia de una copia, que podría llevar a un modelo a generar contenido cada vez más homogéneo y menos preciso”, explicó.
En su último libro, Invisible, Vivas postuló diez principios de la IA. Uno de ellos, el principio de calidad, sostiene que todo aquel contenido generado sintéticamente debe alimentarse de contenido creado por humanos para garantizar sus estándares en el tiempo. “Si todo el contenido que está en internet es creado por IA, los próximos modelos de lenguaje se nutrirán de ese modelo. Y ahí, como sucede con el principio biológico de la consanguinidad, la calidad será cada vez peor”, acotó.
Un estudio publicado en abril ratificó que la acumulación de datos generados por IA acelera el colapso. No obstante, también apuntó una posible solución: combinar datos sintéticos junto con datos originales puede evitar al menos la fase final del efecto de destrucción. Esta técnica, aunque prometedora, no elimina el riesgo por completo, tan solo lo podría atenuar.

Jathan Sadowski, investigador principal del Departamento de Computación Centrada en el Ser Humano de la Universidad de Monash, Australia, acuñó el concepto de Habsburg AI para referirse a lo que poco tiempo después se popularizaría como “el colapso del modelo”. Desde entonces, el interés científico por estudiar el porvenir de la IA generativa se disparó y se comprobó, tal como él intuía, que los sistemas que se entrenan con datos sintéticos tienden a experimentar un colapso.
Según Sadowski, el punto clave es determinar cuántos datos sintéticos son demasiados: “Aún no sabemos cuál es el punto de inflexión. Depende en gran medida de los parámetros específicos de cada modelo y de la calidad de los datos”.
Para el experto, hay un interés concreto de las empresas desarrolladoras por relativizar los riesgos del colapso del modelo, que comienza a sobrevolarles cada vez más cerca. “Es cierto que pueden estar guardando algún conocimiento secreto sobre los avances en datos sintéticos, pero también está muy claro que deben restar importancia a las preocupaciones para mitigar cualquier inquietud de sus inversores”, advirtió.
El uso de datos sintéticos no es de por sí malo. Algunos estudios, de hecho, sugieren que puede ser aceptable si se gestiona de manera responsable. Sin embargo, los expertos coinciden en que la falta de claridad hoy plantea una inquietud urgente tanto para empresas como investigadores: ¿cómo garantizar que los modelos de IA sigan siendo útiles y precisos en el futuro?
Emily Wenger da una alternativa viable, que depende de dos factores: (1) que los proveedores de modelos de IA marquen sus datos con marcas de agua y (2) que estas marcas de agua se compartan con otros entrenadores de modelos para que puedan detectar el contenido sintético.
Los grandes jugadores como Google, OpenAI y Meta ya identifican sus resultados con marcas de agua, pero no está claro si los proveedores más pequeños o menos regulados lo hacen. “Si gran parte del contenido publicado en internet proviene de modelos que no usan marcas de agua o cuya marca de agua no se comparte ampliamente, será muy difícil detectar y eliminar esos contenidos de los conjuntos de datos de entrenamiento”, explicó Wenger.
El futuro de la IA generativa dependerá, en gran medida, de cómo se maneje ese desafío. Las empresas tecnológicas y los investigadores están en una carrera para encontrar soluciones antes de que los efectos negativos del colapso del modelo se vengan encima. Antes de que la burbuja de contenidos explote.
Últimas Noticias
Montaron una empresa en la que todos los empleados son IA y los resultados fueron desconcertantes
Una universidad estadounidense hizo el experimento para medir cuán eficiente es la inteligencia artificial sin supervisión humana. ¿Qué tareas lograron resolver y en cuáles fracasaron? En diálogo con Infobae, los investigadores analizaron los límites en la autonomía de las máquinas

Cada vez nacen menos niños en Argentina: ¿qué medidas pronatalidad funcionan y se podrían aplicar?
La cantidad de nacimientos por año ya está en su mínimo histórico y la caída se profundiza. Algunos países frenaron e incluso revirtieron esa tendencia con ciertas políticas. ¿Se pueden replicar? ¿O el fenómeno es inevitable?

El autor chino que escribió el libro del año no existe: “Lo hicimos la IA y yo”
“Hipnocracia” fue un éxito rotundo y Jianwei Xun ganó una popularidad inusitada, pero se trataba de un experimento. Infobae conversó con Andrea Colamedici, el verdadero responsable, que reveló cómo coescribió el texto junto a dos inteligencias artificiales y qué buscó con la performance

De ser “la carrera del futuro” a la incertidumbre: ¿tiene los días contados con la IA?
La inteligencia artificial sacudió uno de los sectores más dinámicos de los últimos años y las oportunidades laborales ya muestran una caída. Cómo será la reconversión y qué cambios traerá al mercado laboral

Descubrieron en un camping argentino los restos de un animal enorme extinguido hace 10 mil años
En un terreno ubicado en Gualeguaychú, los vecinos encontraron fósiles que no se correspondían con ninguna especie actual. Dieron aviso y los investigadores identificaron que se trataba de un megamamífero de la Edad del Hielo. Sus características y el valor del hallazgo



